异步数据流
 Data streaming is an optimization technique intended to reduce spikes caused by loading graphic resources. With this technique, not all the data is loaded into memory at once. Instead, only the required data is loaded, and the rest is loaded progressively on demand.数据流传输是一种优化技术,旨在减少由于加载图形资源而导致的峰值。使用此技术,并非所有数据都立即加载到随机存取存储器(RAM)中。取而代之的是,仅加载所需的数据,其余所有数据根据需要逐步加载。
Data streaming is an optimization technique intended to reduce spikes caused by loading graphic resources. With this technique, not all the data is loaded into memory at once. Instead, only the required data is loaded, and the rest is loaded progressively on demand.数据流传输是一种优化技术,旨在减少由于加载图形资源而导致的峰值。使用此技术,并非所有数据都立即加载到随机存取存储器(RAM)中。取而代之的是,仅加载所需的数据,其余所有数据根据需要逐步加载。

Resource loading is performed and transferred to the GPU in separate asynchronous threads. After that, resources are synchronized and added to the virtual scene on the CPU side.执行资源加载,并在单独的异步线程中将其转移到GPU。之后,资源将同步并添加到CPU一侧的虚拟场景。
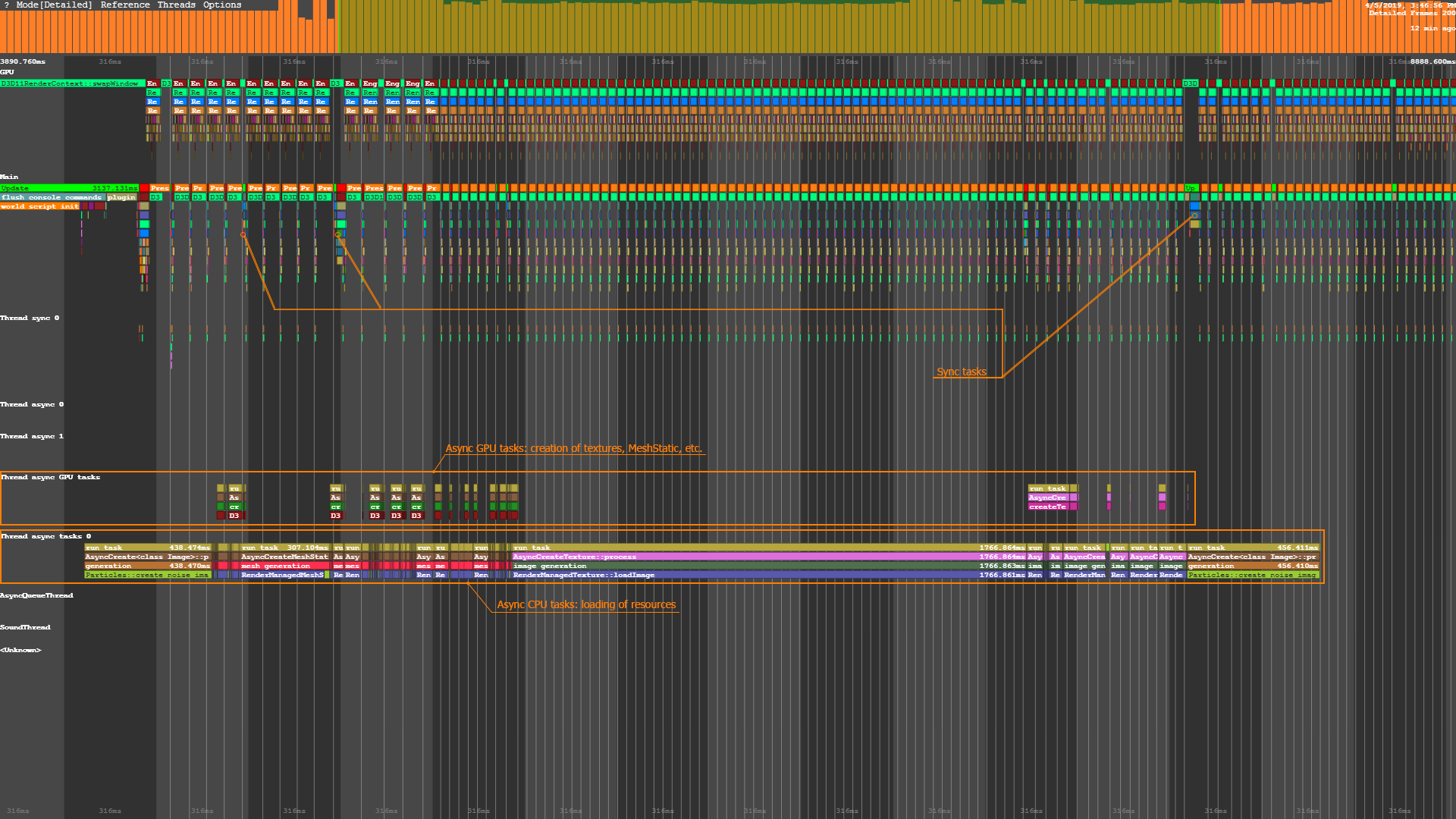
The output of the Microprofile tool. Microprofile工具的输出In UNIGINE, asynchronous data streaming is enabled by default. To disable asynchronous data streaming, enable the Forced mode in the Streaming Settings in the Editor or by using the render_streaming_mode 1 console command. The Forced mode ensures force-loading of all meshes and textures required for each frame at once (e.g., grabbing frame sequences, rendering node previews, warmup, etc.).在UNIGINE中,默认情况下启用异步数据流。要禁用异步数据流,请在编辑器的Streaming Settings中启用Forced模式,或使用 render_streaming_mode 1 控制台命令。 Forced模式可确保强制加载每个帧一次所需的所有网格和/或纹理(例如,抓取帧序列,渲染节点预览,预热等)。
The streaming system provides asynchronous loading of the following data to RAM:流传输系统将以下数据异步加载到RAM:
- All texture runtime files and textures with the Unchanged option enabled, including cubemaps, voxel probe maps, and shadow maps of baked shadows.启用了Unchanged选项的所有纹理运行时文件和纹理,包括 cubemaps , voxel探针图和 baked的阴影图阴影。
- Meshes of ObjectMeshStatic, ObjectMeshClutter, and ObjectMeshCluster objects. ObjectMeshStatic, ObjectMeshClutter和ObjectMeshCluster对象的网格。
You can obtain general information on streamed resources by using the render_streaming_info console command.有关流资源的常规信息,可以使用 render_streaming_info 控制台命令获取。
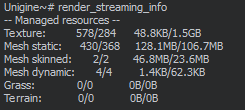
The render_streaming_info output. render_streaming_info输出It is also possible to print the list of loaded resources and detailed information on them by using the render_streaming_list console command.也可以使用 render_streaming_list 控制台命令来打印已加载资源的列表以及有关这些资源的详细信息。
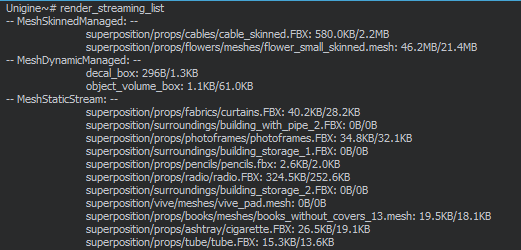
The render_streaming_list output. render_streaming_list输出Procedurally generated objects such as ObjectMeshClutter and ObjectGrass are generated in a separate thread, significantly reducing performance costs.程序生成的对象(例如ObjectMeshClutter和ObjectGrass)是在单独的线程中生成的,从而显着降低了性能成本。
Common Streaming Settings通用流媒体设置#
The Render Budget parameter limits the number of loaded/created graphic resources per frame. Use it to find the balance between loading speed and performance.在一帧中加载/创建的图形资源的数量受Render Budget参数限制。可用于在加载速度和性能之间找到平衡。
To take advantage of multithreading, set the maximum number of threads used for resource streaming by using the render_streaming_max_threads console parameter. A higher number of threads results in faster streaming but may cause spikes in the case of excessive consumption of GPU resources.要利用多线程的优势,请使用render_streaming_max_threads控制台参数设置用于资源流传输的最大线程数。线程数越高,流传输速度越快,但是如果GPU资源的消耗过多,则可能会导致峰值。
The streaming system requires a GPU driver with multithreading support.流系统需要具有多线程支持的GPU驱动程序。By default, the Memory Limit control is enabled. Resources unnecessary for rendering at the moment are unloaded on exceeding specified memory. Maximum memory amounts are defined for meshes, textures, and particles separately via the Memory Limit values specified in a percentage of the total GPU memory.默认情况下,启用Memory Limit控件。当超出指定的内存量时,将卸载当前不需要渲染的网格和纹理。通过Meshes Memory Limit和Textures Memory Limit参数分别为网格和纹理定义了最大内存量,值以总GPU内存的百分比指定。
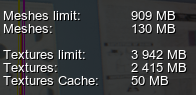
Memory limits and VRAM occupied by streamed resources are available in the Profiler tool. Profiler工具中提供了流资源占用的内存限制和VRAM The graphic resources are regularly checked for being modified in order to be reloaded or deleted. The Destroy Duration defines the corresponding resource cleanup interval in number of frames.定期检查图形资源是否被修改,以便重新加载或删除。相应的间隔由Destroy Duration指定。
All streaming-related settings have their equivalents in the console streaming parameters.所有与流媒体相关的设置都具有与之对应的 控制台流媒体参数 。Texture Cache纹理缓存#
The streaming system uses the texture cache composed of minimized copies generated for all textures with user-defined resolution stored in the data/.cache_textures folder. These copies are used instead of the originals while they are being loaded.流传输系统使用纹理缓存,该纹理缓存由为具有用户定义的分辨率的所有纹理生成的最小化副本组成,并存储在 data/.cache_textures 文件夹中。这些副本将在加载时代替原始文件使用。

Texture cache is loaded at Engine's startup and always stays in the memory after loading. The following default loading order ensures smooth loading and rendering of resources:纹理缓存在引擎启动时加载,并始终在加载后保留在内存中。为了提供流畅的资源加载和呈现,流式实体具有以下加载优先级:
-
Texture cache;
纹理缓存
-
Geometry;
几何形状
-
Uncached textures cause spikes as texture cache is generated for them on the fly; materials with uncached and unloaded textures applied are rendered black;
未缓存的纹理(由于在运行中为其生成纹理缓存时会产生尖峰;应用了未缓存和未加载纹理的材质会呈现黑色)
-
Full-size textures.
全尺寸纹理
Using the textures_cache_preload flag in the boot config file, you can choose the texture cache loading priority — preloaded or loaded after geometry data.可以在几何数据之后预加载或加载纹理缓存,Texture Cache Preload标志控制纹理缓存的加载优先级。
If there is no texture cache in the project, it will be generated for all textures at Engine's startup, causing spikes and extremely increasing loading time (up to several minutes).如果项目中没有纹理缓存,则将在引擎启动时为所有纹理生成纹理缓存,从而导致峰值并极大增加加载时间(长达数分钟)。By default, texture cache files are generated with a resolution of 16 x 16 px. Such a low resolution of textures may be noticeable during loading.默认情况下,生成纹理缓存文件的分辨率为16x16,如此低的纹理分辨率会导致加载过程中出现视觉伪像。可以通过设置Texture Cache Resolution参数来提高分辨率。应该使用render_streaming_textures_cache_destroy控制台命令清除现有的缓存文件,之后将以新的指定分辨率自动生成纹理缓存。
Be aware that higher texture cache resolution requires more video memory.请注意,较高的纹理缓存分辨率需要更多的视频内存。The video memory amount currently occupied by the texture cache is available in the Performance Profiler tool. Performance Profiler工具中提供了纹理缓存当前占用的视频内存量。
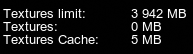
The render_streaming_textures_cache_load and render_streaming_textures_cache_unload console commands enable you to control loading of texture cache. For example, after loading full-size textures, you can unload the texture cache from video memory for better performance. render_streaming_textures_cache_load和render_streaming_textures_cache_unload控制台命令允许控制纹理缓存的加载。例如。加载完整大小的纹理后,可以从视频内存中卸载纹理缓存,以获得更好的性能。
OpenGL SettingsOpenGL设置#
Settings and workflow for OpenGL API are slightly different than for DirectX API. OpenGL API的设置和工作流程与DirectX API略有不同。
Under OpenGL, the Data Streaming System engages two intermediate buffers to provide data transfer between CPU and new resource:在OpenGL下,数据流系统使用两个中间缓冲区来提供CPU与新资源之间的数据传输:
- Async Buffer used for mesh and texture streaming Async Buffer用于网格和纹理流处理
- Async Buffer Indices used for streaming of vertex indices of meshes Async Buffer Indices用于流化网格的顶点索引
The size of the Async Buffer buffer must correspond to the size of the largest resource (mesh/texture); otherwise, in the case of a larger resource, the buffer will be resized, causing a spike. Async Buffer缓冲区的 大小 必须与最大资源的大小(网格/纹理)相对应,否则,在资源较大的情况下,将调整缓冲区的大小,从而导致峰值。
Be aware that the size of these intermediate buffers contributes to the increased total memory consumption.请注意,这些中间缓冲区的大小将添加到总内存消耗中。The Async Buffer Synchronization parameter stands for the mechanism of buffer synchronization. So, async buffers are created only once and then synchronized, reducing the time on allocating and freeing memory. When the synchronization is disabled, both Async Buffer and Async Buffer Indices are created anew for each new resource. This reduces the number of buffer synchronizations but increases the number of memory allocations.如果将Async Buffer Synchronization参数设置为 1 ,则启用缓冲区同步机制。因此,异步缓冲区仅创建一次,然后进行同步,从而减少了分配和释放内存的时间。禁用同步后,将为每个新资源重新创建Async Buffer和Async Buffer Indices。这减少了缓冲区同步的次数,但增加了内存分配的数量。
Sometimes (depending on the hardware/driver used, e.g., when the main thread is affected by synchronization primitives in other threads), memory allocation may be faster than synchronizations; in such cases, when streaming becomes unacceptably slow, it is recommended to disable buffer synchronization.有时(取决于所使用的硬件/驱动程序,例如,当主线程受到其他线程中的同步原语影响时),内存分配可能比同步要快;在这种情况下,当流变得异常缓慢时,建议禁用缓冲区同步。
There are some known issues and workarounds for some hardware/driver software:一些硬件/驱动程序软件存在一些已知的问题和解决方法:
- The Mesa 3D GL: The buffer synchronization must be disabled (gl_async_buffer_synchronization 0) for better performance. The updated Open Graphics Drivers are required. The Mesa 3D GL:必须禁用缓冲区同步(gl_async_buffer_synchronization 0),以获得更好的性能。需要更新的 Open Graphics Drivers 。
- Intel: It is necessary to consider that VRAM is limited by OS to one-half of RAM. Intel:有必要考虑到VRAM受操作系统限制为RAM的一半。