Double Precision Coordinates
There are cases when you need to calculate very large numbers (e.g. the distances in space), or, conversely, very small numbers (e.g. the distances in microcosm). In this regard, Unigine features a 64-bit double-precision floating-point format (instead of the 32-bit single-precision one) to define coordinates of objects in the virtual scene. Therefore, it is possible to create highly detailed virtually unlimited worlds (the maximum coordinates values are effectively 536,870,912 times larger than for the 32-bit float precision).
In reality, float precision limitations are noticeable even on scenes larger than 10x10 km due to the accumulation of positioning errors, so double precision should be used for anything larger to maintain accuracy.
Single Precision versus Double Precision
In computing, floating point is a method of representing a real number by means of a mantissa and an exponent:
mantissa × base ^ exponent ,
where base is equal to 2.
The IEEE Standard for Floating-Point Arithmetic (IEEE 754) is a technical standard used both for float-precision and double-precision floating point formats. The single-precision floating point format occupies 32 bits (4 bytes), the double-precision floating point format occupies 64 bits (8 bytes). The number formats for both cases can be seen at the picture below:
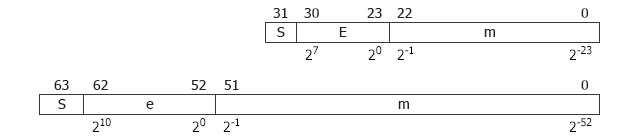
Where:
- S - sign (0 - positive; 1 - negative)
- E - exponent (127 for single, 1023 for double)
- m - mantissa [1;2]
The distribution for the floating point format (both single and double) is subnormal. For instance, we have -1 ≤ E ≤ 2:
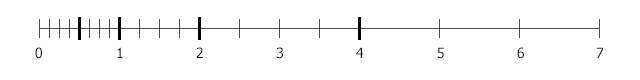
The possible values range for single and double precision, as well as the minimal possible gradations are shown at the picture below.

- Values range: [-10^9;+10^9]. The lower and higher values will be displayed as inf.
- The maximum quantity of the numbers in the fractional part cannot be more than 3.
Values set by means of UnigineScript functions have only format's limitations.
Errors
Usage of a single precision floating format leads to inaccurancies in calculations shown below.
Positioning Error
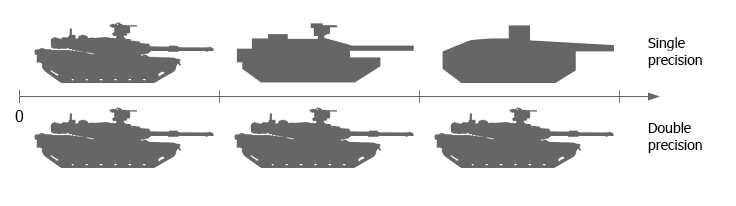
The large distance between possible graduations in the single-precision floating point leads to the positioning errors. The picture below schematically demonstrates the positioning while using single and double precision:
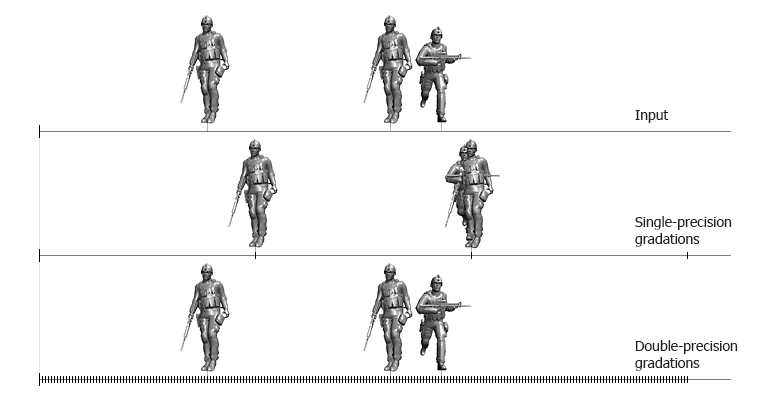
In the virtual scene, object transformations (including locating, rotating and scaling), animation and physics implementation lead to a positioning error, which, in turn, cause objects jittering. To avoid this problem and to provide far more precise positioning, use the double-precision floating point coordinates. Besides, positioning errors may lead to a vertex collapse that can be schematically seen at the picture below.
Error Accumulation
As the numbers of the IEEE 754 format present a finite set, onto which the infinite set of real numbers is transmitted, the output value may consist a representation precision error, which in further calculations cause the error accumulation. The function of the error is shown below:
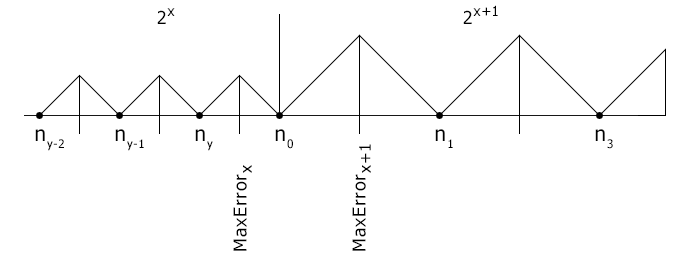
The maximum absolute error for a number is equal to the half of the possible gradation. As the possible gradation is doubled when the exponent is incremented, the error is increased too.
The gradation of the numbers equals to 2 ^ (E-150) for single-precision numbers, and 2 ^ (E-1075) for double-precision numbers.
Lets compare the 1 value for both single-precision and double-precision numbers.
| Single | Double | |
|---|---|---|
| Number, dec | 1.0 | 1.0 |
| IEEE754, hex | 3F800000 | 3FF00000 00000000 |
| Absolute error, dec | 2 -23 ≈ 1.192*10 -7 | 2 -52 ≈ 2.220446*10 -16 |
| Relative error, % | 11.9209*10 -6 | 2.220446*10 -14 |
According to the distribution, the gradation values are increasing, which leads to the error increase. But in comparison, the double-precision numbers error is many times less than the single-precision numbers errors.